컴퓨터 네트워크에 관하여
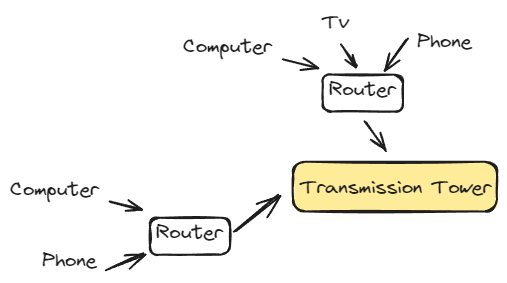
우리가 흔히 사용하는 네트워크의 구성은 위와 같이 구성되어 있습니다. 네트워크를 이용할 때 우리는 Hot, Client에 해당하는 컴퓨터, TV, Computer와 같은 기기를 이용하여 네트워크 장비에 해당하는 Router, Modem을 이용하여 ISP에서 제공하는 네트워크를 LAN 선으로 연결하여 네트워크를 사용하고 있습니다. 모든 네트워크에 관한 구성과 장비를 위와 같지 않지만 최대한 단순하게 구성할 경우 위와 같이 표현할 수 있습니다.
범위에 따라 다른 네트워크 명칭
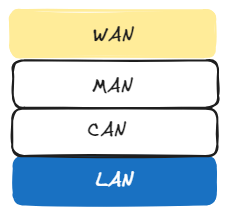
네트워크는 범위에 따라서 구분이 됩니다. 우리가 흔히 집에서 사용하는 선을 연결하여 인터넷을 사용하는 방법은 LAN에 해당합니다. LAN은 Local Area NetWork의 약자로 네트워크의 범위에서 가장 좁은 범위에 해당합니다.
LAN의 특징은 뭐가 있을까? LAN의 장점이라고 폐쇄적이라는 점이 있습니다. LAN은 선을 통해 인터넷을 사용하기 때문에 다른 네트워크 연결에 영향을 받지 않아 안정적으로 네트워크를 사용할 수 있다는 장점이 있습니다. 하지만 외부에서 다른 LAN을 사용하는 네트워크와 데이터를 주고 받기 위해서는 새로운 연결을 하기 위해서는 추가적인 네트워크 장비가 필요합니다.
LAN이외에도 우리가 많이 이용하는 것은 WAN이 있습니다. WAN은 World Area Network의 약자로 가장 넓은 범위에 해당하는 네트워크 용어에 해당합니다. WAN은 개인이 감당할 수 있는 네트워크가 아니기 때문에 우리는 주로 ISP에 돈을 지불하고 네트워크를 사용하는 방법으로 WAN을 사용합니다. 굉장히 익숙한 방법이지 않나요? 우리가 SKT,LG,KT에 통신비를 지급하고 인터넷을 사용하는 방식이 WAN을 사용하고 있는것이기 때문입니다.
이외에도 CAN(Campus Area Network) MAN(Metropolitan Area Network)이 있지만 이에 대해서 자세하게는 다루지 않겠습니다.
네트워크를 이용하여 뭘 보낼까?
우리가 네트워크를 사용하는 주된 이유는 무엇인가요? 유튜브로 동영상을 보거나 스트리밍 서비스를 이용하여 음악을 듣거나 문자를 보내거나 하는 용도등등으로 네트워크를 가장 많이 사용할 것입니다. 이러한 행위는 모두 네트워크를 통해 데이터를 요청(Request)하거나 요청 받은 데이터에 적합한 응답(Response)을 하여 데이터를 주고 받는 행위 입니다. 그리고 이러한 데이터의 단위를 패킷(Packet)이라고 부릅니다.
데이터, 메시지의 교환 방식은 뭐가 있을까?
우리가 가장 흔히 사용하고 있는 메시지 교환 방식은 회선 교환 방식 또한 주된 메시지, 데이터 교환 방식입니다. 회선 교환 방식은 우리가 멀리 떨어져 있는 상대와 전화하는 것을 생각하시면 됩니다. 전화의 특징은 어떻게 될 까요? 우선 회선이 연결되어 있어야 합니다. 이를 위해 회선 스위치를 이용하여 저와 상대방 간의 회선을 적절하게 설정하여 회선을 연결하게 됩니다. 또 다른 특징은 우리가 누군가와 통화하고 있을 경우 다른 사람은 저와 다른 사람의 통신에 간섭할 수 없습니다. 이러한 일이 일어나는 이유가 무엇일까요? 이는 이미 저와 다른 상대가 특정 회선을 사용하고 있기 때문에 다른 사람들은 그 회선을 사용할 수 없는 것입니다. 이러한 특징이 회선 교환 방식에 단점이기도 합니다. 하나의 회선을 사용하고 있기 때문에 다른 사용자가 회선을 사용하기 위해서는 현재 사용하고 있는 사용자가 회선의 사용을 끝나길 기다려야하니 회선의 이용 효율이 낮아질 수 있고 회선에 메세지가 흐르고 있지 않을 경우 해당 회선은 불필요한 공간을 차지하고 있는 것이기 때문에 가능한 모든 회선에 메시지가 흐르고 있어야만 효율이 높아질 수 있다는 단점이 존재합니다.
앞서 네트워크를 통해 주고 받는 데이터의 단위를 패킷이라 말했고 이는 메시지에 속합니다. 네트워크를 이용하여 메시지를 주고 받는 방식은 패킷을 주고 받는 패킷 교환 방식 입니다. 패킷 교환 방식의 특징은 어떤 것이 있을까요? 앞서 설명했던 회선 교환 방식의 장점은 연결되어 있는 회선으로 일정양의 데이터를 일정하게 주고 받을 수 있다는 장점이 있지만 회선 한개를 통째로 사용해야 한다는 단점이 있습니다. 패킷 교환 방식은 이러한 단점을 해결한 방법입니다. 어떻게 이 방법을 해결했을까요? 호스트, 내가 보내고자 하는 데이터를 여러개의 작은 패킷으로 쪼개서 네트워크를 통해서 전달하는 방법을 사용함으로써 이를 해결하고자 했습니다. 회선 경로를 점유하지 않고 쪼개어진 패킷을 계속해서 전송함으로써 회선의 효율성을 높이는 방법을 사용함으로써 이 문제를 해결했습니다. 그리고 이러한 쪼개진 패킷을 손실없이 수신지까지 전송하기 위하여 경로를 결정하고너 패킷의 송수신지를 식별할 수 있게끔 하는 **패킷 스위치(라우터, 스위치)**를 사용합니다.
쪼개진 패킷은 어떻게 수신지로 도착할까?
앞서 쪼개진 패킷이 경로를 점유하지 않고 전달이 된다는 말은 여러개의 데이터들이 여러가지로 뒤섞여서 전송이 된다는 것을 의미합니다. 그렇다면 이렇게 뒤섞여 있는 데이터 중 어떤 패킷이 어디로 가는 것인지 구분할 수 있는 방법은 뭐가 있을까요? 패킷을 하나의 택배상자라고 생각 해볼까요? 택배상자가 도착지에 제대로 도착하기 위해 필요한 정보는 무엇일까요? 도착지에 대한 정보, 수신자에 대한 이름과 전화번호, 도착지에 대한 주소, 내용물들이 필요하겠죠? 패킷또한 마찬가지입니다. 수신지에 제대로 도착하기 위한 도착지의 정보를 포함하고 있는 헤더, 트레일러를 통해서 구분하고 또한 택배 상자의 내부 내용에 해당하는 페이로드를 포함하고 있습니다.
네트워크 계층 이야기
패킷에 대한 내용을 자세하게 이어가기 전에 네트워크에 대한 내용을 먼저 이야기해야 합니다. 이유가 무엇일까요? 택배 배송원 분이 빠르게 수신지로 가기 위해서 필요한 것은 무엇일까요? 수신자에 대한 정보 또한 필요하겠지만 제대로 정비되어 있는 경로와 도로 시스템등이 제대로 갖추어져야 빠르게 도착할 수 있습니다. 그렇기 때문에 네트워크에 대해서 먼저 살펴볼 필요가 있는 것입니다!
프로토콜( Protocol )
프로토콜은 네트워크를 통해서 제대로 정보를 전달하기 위하여 정보를 올바르게 주고받기 위해 합의된 규칙이나 방법을 뜻합니다. 예를 들어 생각해봅시다. 제주도에 사시는 분이 제주도 특유의 방언으로 도착자에 대한 정보를 작성했다고 가정해봅시다. 이 택배를 전달하시는 분은 이 사투리에 대한 지식이 전혀 없을 경우 택배는 제대로 도착할 수 있을까요? 그렇지 않을 것입니다! 이러한 문제, 메시지를 주고 받는데 있어 이해할 수 있는 언어로 데이터를 전송할 것을 합의한 규칙이 바로 프로토콜입니다.
이러한 프토토콜의 예시로는 IP(Internet Protocl) 네트워크를 이용하여 패킷을 주고 받기 위하여 정의된 프로토콜, ARP(Address Resolution Protocol) IP주소가 MAC주소에 대응하기 위하여 정의된 프로토콜, HTTPS , HTTP등이 모두 프로토콜에 해당합니다. 앞에서 볼 수 있듯이 모든 프로토콜에는 목적과 특징이 있습니다.
네트워크 참조 모델
네트워크 참조 모델에는 OSI 모델과 TCP/IP 모델로 구분이 됩니다. 이때 OSI 모델은 이상적인 네트워크 계층 모델이라고 구분이 되고 TCP/IP 모델의 경우 실질적으로 사용되는 네트워크 계층 모델이라고 구분이 됩니다. OSI 계층 모델은
- 응용 계층
- 표현 계층
- 세션 계층
- 전송 계층
- 네트워크 계층
- 데이터 링크 계층
- 물리 계층
위의 계층의 순서에 따라 네트워크는 사용자로부터 네트워크 장비까지 계층을 따라 이동하며 네트워크를 사용하게 됩니다. 다음은 TCP/IP 모델입니다.
- 응용 계층
- 전송 계층
- 인터넷 계층
- 네트워크 액세스 계층
위와 같은 계층은 실질적으로 네트워크를 이용하여 데이터를 주고 받을 때의 흐름을 나타내기 위한 계층으로서 구분이 됩니다. 그래서 실질적으로 사용되는 네트워크 계층에 포함되는 것이 TCP/IP 모델이라고 설명하고 있습니다.
캡슐화와 역캡슐화
캡슐화는 코드를 작성하면서도 많이 들어보셨을 만한 용어입니다. 네트워크에서 캡슐화는 OSI 모델의 계층에 따라 데이터가 전달이 되며 변경이 되는 과정을 캡슐화라고 합니다. 네트워크에서 가장 사용자와 가까운 위치에 있는 응용계층에서 부터 데이터가 계층 아래로 이동하면서 물리 계층에 있는 네트워크 장비를 통해서 다른 사용자 비트를 전달됩니다. 그리고 전송한 비트를 상대방이 물리 계층에서 받아서 응용계층으로 올라가 사용자에게 데이터가 도착하는 과정을 역캡슐화라고 합니다. 이러한 일련의 과정을 통해서 사용자가 네트워크를 통해서 데이터를 주고 받고 할 수 있게 됩니다.
앞서 캡슐화에 대해서 설명할 때 계층에서 비트와 데이터라고 구분하여 표현한 것을 보실 수 있습니다. 이러한 이유가 바로 PDU가 다르기 때문입니다. PDU는 각 계층에서 송수신되는 메시지의 단위를 PDU라고 표현합니다. 각 계층에서 전송되는 메시지를 뭐라고 명칭하는지 살펴보겠습니다.
- 응용 계층, 표현 계층, 세션 계층 : 데이터(data)
- 전송 계층 : 세그먼트(segment), 데이터그램(datagram)
- 네트워크 계층 : 패킷(packet)
- 데이터 링크 계층 : 프레임(frame)
- 물리 계층 : 비트(bit)
이렇게 각 계층에서 전달 되는 메시지를 굳이 달리 표현하는 이유가 무엇일까요? 이는 각 메시지에 포함되어야 하는 정보가 다르기 때문입니다. 우선 기본적으로 모든 계층에 포함되는 메시지는 **페이로드(payload)**입니다. 페이로드는 사용자가 실질적으로 사용자가 전달하고자 하는 데이터입니다. 페이로드 이외에도 **헤더(header)**가 전송되는 모든 메시지에 포함됩니다. 하지만 헤더에 포함되어 있는 데이터는 모두 다른 메시지를 포함하고 있는데 이는 각 계층에서 수행하는 역할이 다르기 때문입니다. 이에 대해서는 앞으로 단원을 진행하면서 정리하겠습니다.
물리 계층의 MAC 주소
MAC주소, 물리적 주소만으로는 다른 네트워크에 속한 호스트의 도달 경로를 파악하여 데이터를 전송하는 것에는 한계가 있다. 이러한 한계로 인해 IP 주소가 필요한 것이다. IP 주소는 택배로 비유할 경우 도로명 주소에 해당하고 MAC 주소의 경우 수신자의 이름에 해당한다고 할 수 있다. IP는 크게 IPv4, IPv6로 나눌 수 있다. 이 둘의 주요한 차이는 주소를 다루는 비트의 수의 차이가 있다. IPv4의 경우 123.2.2.1과 같은 방식으로 8비트의 4개의 숫자로 구성이 된다. 반면 IPv6의 경우 2003:adbc:a2391:dddd:0000:0000:aaaa:1111와 같이 16비트로 구성되어 있는 수로 주소가 형성이 된다는 것의 차이가 있다. IP의 주요한 기능은 IP 주소 지정(addressing)과 단편화(fragment)가 있다. IP 주소 지정은 말 그대로 데이터가 도착할 주소를 지정하는 역할을 한다. 이 경우 기존의 페킷의 데이터에 추가적인 정보들을 추가하여 기능을 수행한다.
IP패킷 헤더의 구성요소
- 식별자, 플래그, 단편화 오프셋, TTL, 프로토콜, 송신지 IP 주소, 수신지 IP 주소
식별자의 경우 각각의 패킷에 동일한 식별자를 부여하여 패킷이 섞이는 상황을 방지하기 위한 방법이다. TTL은 Time To Live의 약자로 데이터의 유통기한이라고 생각하면 된다. TTL은 라우터를 지날 때마다 남은 TTL 기간을 나타내는 단위인 홉(Hope)이 감소하게 된다. 홉이 모두 감소 하였을 경우 해당 패킷은 폐기가 되는데 이러한 기능이 있는 이유는 네트워크 내부에 불필요한 데이터가 오랫동안 방치되는 현상을 방지하기 위한 역할을 수행한다. 플래그는 3개의 0 또는 1의 데이터로 표현이 되는데 가장 앞에 있는 0은 항상 0으로 표기가 되고 이후 DF, MF의 용도로 사용이 된다. DF는 Don't Fragment의 약자로 해당 패킷은 단편화가 일어나서는 안된다는 것을 표기한다. MF는 More Fragment 남은 단편화 데이터가 더 존재함을 표기한다. 단편화 오프셋은 단편화된 데이터들의 거리를 나타내는 용도로 사용이 되며 데이터가 뒤바뀌는 일이 생기지 않게 하기 위해서 사용된다. 프로토콜은 말그대로 어떤 프로토콜인지 표기하며 나머지 두가지도 표기와 같다. 단편화는 패킷을 여러개의 데이터로 쪼개는 것을 이야기한다. 쪼개는 이유는 데이터의 최대 전송량을 나타내는 MTU(Maximum Transimission Unit)이 제한되기 때문이다. 단편화를 이용하여 크기가 큰 데이터를 전송할 수 있게끔 하기 위해서 여러개의 데이터로 쪼개서 전송 하는 것이다. 하지만 이러한 단편화가 많이 일어나는 것은 네트워크에 부담을 주고 대역폭을 감소 시킬 수 있기 때문에 가능한한 적게 사용되는 것이 좋다. 이러한 것을 수행하기 위하여 최대 전송량 탐색 기능을 활용하여 전송하는 IP의 최대 MTU가 몇인지 파악하고 최대 전송량에 맞춰 패킷을 나누어 전송하는 것이 가장 일반적이다.
ARP는 같은 네트워크에 속해 있는 IP의 MAC 주소를 알아내기 위한 방법이다. IP 주소만으로 정확한 네트워크 경로를 알아내기 어렵기 때문에 해당 방법을 이용하여 MAC 주소를 알아내 정확하게 데이터를 전송하기 위하여 고안된 방법이다. ARP는 특정 패킷을 동일한 네트워크에 브로드 캐스트 방식으로 데이터를 전송하고 해당 패킷의 목적지에 해당하는 IP가 이 패킷에 응답할 경우 해당 IP에 대한 주소와 MAC을 테이블에 저장하여 해당 주소로 다시 데이터를 전송할 경우 브로드캐스트를 이용하지 않고 직접 데이터를 전송할 수 있게 된다. 이때 동일한 네트워크에 속해야 한다는 제한을 두었는데 이론상 다른 네트워크에도 ARP를 적용이 가능하지만 이 방법은 효율적이지 않기 때문에 다른 방법을 사용하여 다른 네트워크의 주소를 알아내는 방법이 사용이 된다.
IP 주소
대중적으로 가장 잘 알려져 있는 IP는 IPv4와 IPv6입니다. 이는 버전의 차이기 있지 가장 큰 차이는 패킷의 헤더에서 표현 가능한 데이터의 크기 및 포함하고 있는 데이터의 차이가 가장 큰 차이입니다. 지금 이야기할 대상은 IPv4입니다. 우선 IPv4의 헤더에 포함되어 있는 데이터에 대해서 다루어보겠습니다.
- 클래스 IP 주소 체계
IP 주소를 구성하는 주소는 호스트의 주소와 네트워크 주소로 구분이 됩니다. 네트워크 주소는 네트워크 ID, 네트워크 식별자 등우로 부르기도 하며 호스트 주소는 호스트 ID, 호스트 식별자 등으로 불리기도 합니다. 172.16.12.45 이 주소를 예시로 설명을 하자면 네트워크 계층의 경우 172.16 이고 호스트 주소의 경우 12.45 이렇게 구분하여 표현됩니다. 이때 각각의 점을 옥텟이라고 부르고 이 예시의 경우 호스트 주소는 2옥텟으로 구성이 되어 있고 네트워크 주소 또한 2옥텟으로 구성이 되어 있습니다. 클래스 주소 체계는 이러한 옥텟의 크기를 구분하여 사용합니다. 예시를 통해서 설명하겠습니다.
- A클래스 : 네트워크 주소. 호스트 주소. 호스트 주소. 호스트 주소
- B클래스 : 네트워크 주소. 네트워크 주소. 호스트 주소. 호스트 주소
- C클래스 : 네트워크 주소. 네트워크 주소. 네트워크 주소. 호스트 주소
이와 같이 클래스를 나눈 이유는 무엇일까요? 그것은 표현할 수 있는 주소의 비트 수를 늘리기 상황에 맞춰서 늘리기 위해서 입니다. 네트워크의 크기에 따라 IP 주소를 다르게 분류하여 호스트의 주소가 더 많이 필요한 경우에는 A클래스를 사용하는 것과 같이 변경하여 사용할 수 있습니다.
- 클래스 리스 IP 주소 체계
하지만 이러한 클래스풀 네트워크 주소 체계는 단점이 명확합니다. 위와 같이 클래스를 나눈다고 하여도 표현할 수 있는 비트의 갯수는 오늘날에 사용되는 네트워크 주소들을 커버하기에는 턱 없이 부족한 수라는 것입니다. 이러한 단점을 보안하고자 등장한 것이 클래스리스 주소 체계입니다. 클래스리스의 경우 서브넷 마스크를 기준으로 호스트 주소와 네트워크 주소를 구분하여 사용합니다. 여기서 서브넷 마스크는 무엇일까요? 서브넷 마스크는 기존의 클래스 체계에서 네트워크 주소의 경우 1, 호스트 주소의 경우 0으로 비트열을 표기한 것을 의미합니다.
동적 IP 주소 할당 DHCP 프로토콜
DHCP 프로토콜, 이외에도 여러 네트워크는 서버와의 메세지를 계속 주고 받으면서 결정 짓게 됩니다. DHCP도 DHCP 서버라고 불리는 서버와 클라이언트가 메세지를 주고 받으면서 결정이 됩니다. 클라이언트는 DHCP 서버에게 DHCP Discover 메세지를 브로드캐스트 방식으로 메시지를 전송하여 메시지를 전달 받은 DHCP서버가 할당이 가능한 IP 주소가 있을 경우 이 IP 주소가 어떠니 클라이언트에게 제안하는 DHCP Offer 메세지를 전송합니다.